首页
热门导航
 中文(中国)
中文(中国)
- English
- 中文(中国)
- Русский
- 한국어
- עִבְרִית
中文(中国)




Panopticon
为资本市场和其他苛刻环境提供流式数据可视化
•视觉异常检测
•内置的实时和时间序列数据
•在排名前15位的金融机构有12个用于该产品
Panopticon Designer
快速在桌面上创建可视化应用程序
Panopticon Server
通过丰富的HTML5客户端在整个企业中部署

顾客
最终用户
我们的技术被全球金融机构广泛采用,包括买方,卖方和交易所。 代表性客户包括:
•纳斯达克,新加坡,汇丰银行,花旗,富达,城堡,黑石,德意志银行,瑞士信贷,瑞银,BAML
OEM
我们在过去十年中与我们的OEM合作伙伴建立了良好的合作关系。 每个合作伙伴都采用我们的视觉分析功能,并将其嵌入到他们的业务解决方案中,涵盖交易,风险和合规性。 代表性客户包括:
•Imagine软件,Factset(端口),SkyRoad,Tibco,Thomson Reuters,OneTick,Nasdaq SMARTS,Dell Statistica
技术合作伙伴
我们只有基础数据基础设施。 因此,我们与CEP,tick数据库,实时数据库,实时立方体和大数据领导者合作。 合作伙伴包括:
•kx,OneTick,Tibco,Datastax,Cloudera

举例
Panopticon用于各种行业和场景。
•交易
•风险与财务
•合规性
•操作
•投资管理MI
•IOT
从技术上说
平面设计师
•MS Windows操作系统(XP,Vista,7,8,8.1,10,2008,2012)与.NET 4. 2GB可用磁盘空间和4GB可用内存
.NET的Panopticon服务器
•Windows操作系统(Vista,7,8,8.1,10,2008,2012),使用.NET 4.5,MS IIS 7至7.5。 4GB可用磁盘空间和8GB可用内存。在内存缓存中限制为可用的服务器RAM
Java的Panopticon服务器
•Apache Tomcat 7或8. MS Windows操作系统(如上所述)或LINUX Redhat / SUSE。 4GB可用磁盘空间和8GB可用内存。在内存缓存中限制为可用的服务器RAM。
HTML的Panopticon分析师
•MS IE 9+,Firefox 10+,Chrome 15+,Safari 5+和500 MB可用内存。通过MS Windows,iOS和Android认证
支持的数据源和功能的完整列表可在技术概况表中找到
访问完整的文档集

即时性
•通过主动订阅操作数据源来实时监控活动。 当新数据推送到分析仪表板时,业务的最新状态将自动显示和更新。 可以随时暂停更新,并且与历史数据的集成允许实时识别异常,并通过进入视图来查看问题如何发展以及然后进入历史视图以识别历史事件来进行调查。
无缝兼容
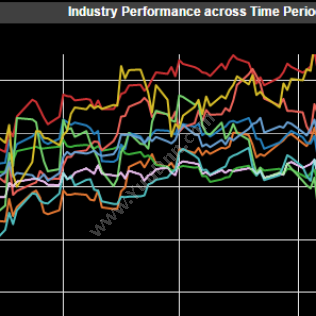
时间序列
•从数年的数据缩小到毫秒的精度
•Conflate,interpolate,聚合和可视化
•按时间或通过事务回放时间序列
•与记录历史/时间序列数据库集成
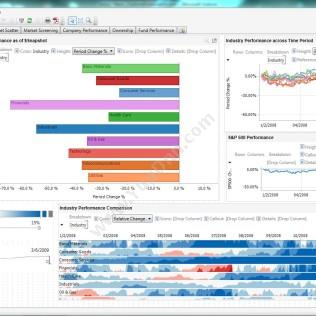
视觉分析
•高密度显示器,用于突出显示整体位置背景下的异常
•是否数值相关,类别相关,同行比较和层次结构,趋势分析和时间序列


连接
•与标准源一起,我们连接到实时,日内更新和历史源
•在可能的情况下预订(推送)数据,或在定义的自动刷新期间轮询(拉出)数据,从1秒到1天。 来源包括:Tick数据库,CEP引擎,消息总线,Web,多维数据集和大数据

大数据
•我们连接到大数据生态系统,从Kafka的实时流订阅,通过Spark的内存分析,到Hive的批量加载。 大数据水库通过适当的连接来提供响应性操作分析。
•Hadoop Hive,Cloudera Impala,Apache Spark SQL,Apache Cassandra,Apache Kafka

统计分析
•基本计算和聚合在产品中原生支持。 通过R或Python提供更复杂的统计功能,既支持数据源,也支持数据管道中的数据转换步骤。 典型的用途包括曲线插值和聚类。
 100%正品
100%正品 运费说明
运费说明 签收提示
签收提示 资料下载
资料下载 增值服务
增值服务 版权声明
版权声明



1. 产品送达用户之日起 7 日内,出现“性能故障”,经由用户所购产品的生产厂家指定维修服务机构检测属实后,可以免费换货;
2.产品送达用户之日起,主机享有 12 个月保修服务,配件享有 6 个月保修服务。

1、若产品主机符合保修条件,根据保修卡与购机发票即可享受保修服务,若无法提供购买证明及保修卡,则以到货签收时间作为保修起算标准;
2、属非保修产品,用户所购产品的生产厂家指定维修服务机构做保外收费维修处理;
3、产品修复后相同的故障经用户所购产品的生产厂家指定维修服务机构检验属实后,享有 3 个月保修服务;
4、需要维修或检测的产品,向用户所购产品的生产厂家指定维修服务机构送修或检测过程中发生的运输、发货和处置费用由用户承担;维修或检测产品寄还用户时产生的运费由用户所购产品的生产厂家承担(仅限中国大陆境内);
5、需要维修或检测的产品,请用户及时备份机器内的数据。用户所购产品的生产厂家不对因数据丢失造成的损失负责;
6、产品在保修期内,维修中正常使用的零部件免费;
7、维修中被替换下来的零部件所有权归用户所购产品的生产厂家所有;
8、用户所购产品的生产厂家不对非产品标准配置的及未经公司认证的配件、软件或应用负责;
9、平台产品均按照国家三包政策执行(产品在未拆封的情况下),个别产品除外,如:定制产品,项目产品等。
10、本条款未尽事宜参考国家三包法律规定。

1、产品无购机发票和保修卡,亦不能在用户所购产品的生产厂家查询到相关的销售信息,且出库日期超过 12 个月;
2、产品主机和配件曾受到:非正常或错误的使用、非正常条件不当的存储、未经授权的拆卸或改动、事故、不恰当的安装造成的损害;
3、由于用户不当造成的损害,如液体注入、外力受损等;
4、未按产品使用说明书的要求进行使用,维修保养或以外运输造成的损坏;
5、 产品的损坏由外部包括但不限于卫星系统、地磁、静电、物理压力等非正常不可预测的因素引起的;
6、因不可抗力如地震、水灾、战争等原因造成的损坏;
7、其它不符合三包相关规定的情况。


您好,有什么能帮助您
2022-05-08 09:35您好,有什么能帮助您
2022-05-08 09:35
此用户没有填写评价内容
2022-05-08 09:35
此用户没有填写评价内容
2022-05-08 09:35
此用户没有填写评价内容
2022-05-08 09:35
此用户没有填写评价内容
2022-05-08 09:35